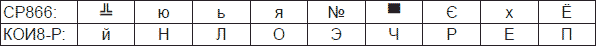При вводе текстовой информации в
компьютер символы (буквы, цифры, знаки) кодируются с помощью различных
кодовых систем, которые состоят из набора кодовых таблиц, размещенных на
соответствующих страницах стандартов для кодирования текстовой
информации. В таких таблицах каждому символу присваивается определенный
числовой код в шестнадцатеричной или десятичной системе счисления, т. е.
кодовые таблицы отражают соответствие между изображениями символов и
числовыми кодами и предназначены для кодирования и декодирования
текстовой информации. При вводе текстовой информации с помощью
клавиатуры компьютера каждый вводимый символ подвергается кодированию,
т. е. преобразуется в числовой код, при выводе текстовой информации на
устройство вывода компьютера (дисплей, принтер или плоттер) по числовому
коду символа строится его изображение. Присвоение символу определенного
числового кода является результатом соглашения между соответствующими
организациями разных стран. В настоящее время нет единой универсальной
кодовой таблицы, удовлетворяющей буквам национальных алфавитов разных
стран.
Современные кодовые таблицы включают в себя
международную и национальную части, т. е. содержат буквы латинского и
национального алфавитов, цифры, знаки арифметических операций и
препинания, математические и управляющие символы, символы псевдографики.
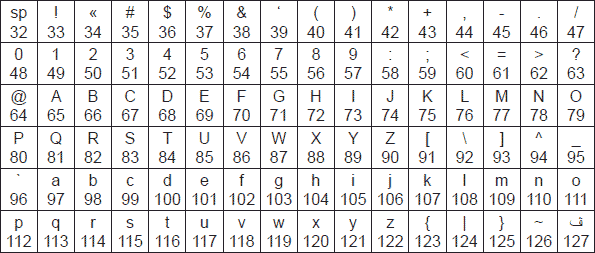
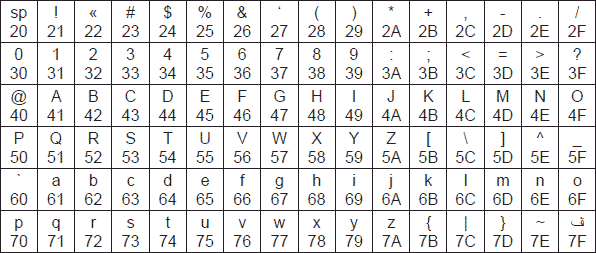
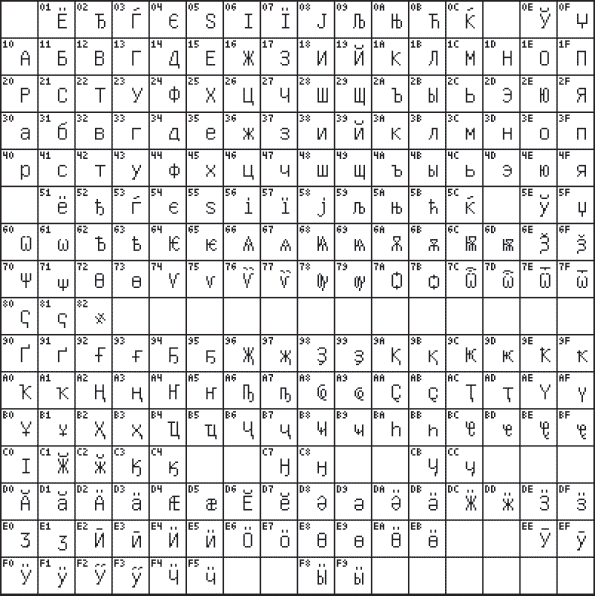
Международная часть кодовой таблицы, базирующаяся на стандарте ASCII (American Standard Code for Information Interchange), кодирует первую половину символов кодовой таблицы с числовыми кодами от 0 до 7F16, или в десятичной системе счисления от 0 до 127. При этом коды от 0 до 2016 (0 ÷ 3210)
отведены функциональным клавишам (F1, F2, F3 и т. д.) клавиатуры
персонального компьютера. На рис. 3.1 приведена международная часть
кодовых таблиц, основанная на стандарте ASCII. Ячейки таблиц пронумерованы соответственно в десятичной и шестнадцатеричной системе счисления.
а) б) Рис 3.1. Международная часть кодовой таблицы (стандарт ASCII) с номерами ячеек, представленных в десятичной (а) и шестнадцатеричной (б) системе счисления
Национальная часть кодовых таблиц содержит коды национальных алфавитов, которую называют также таблицей наборов символов (charset).
В настоящее время для поддержки букв
русского алфавита (кириллицы) существует несколько кодовых таблиц
(кодировок), которые используются различными операционными системами,
что является существенным недостатком и в ряде случаев приводит к
проблемам, связанным с операциями декодирования числовых значений
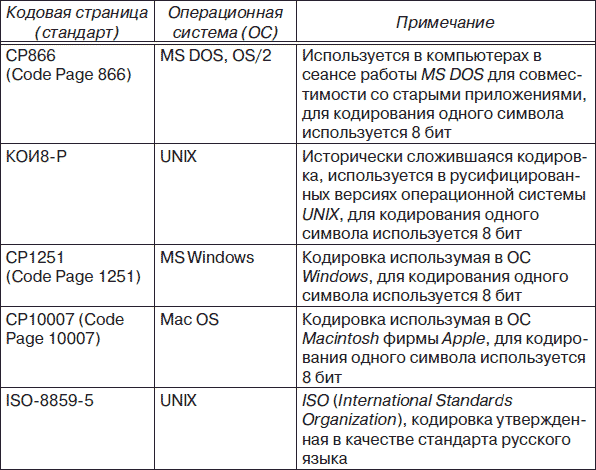
символов. В табл. 3.1 приведены названия кодовых страниц (стандартов),
на которых размещены кодовые таблицы (кодировки) кириллицы.
Таблица 3.1Одним
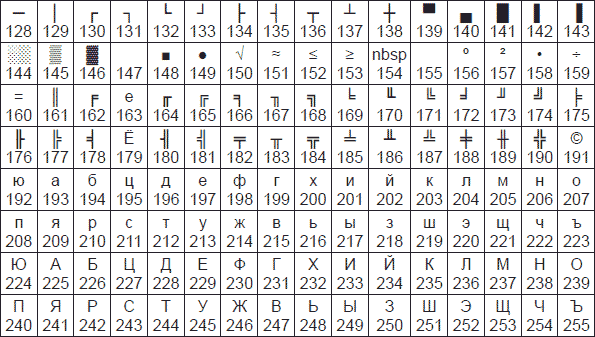
из первых стандартов кодирования кириллицы на компьютерах был стандарт
КОИ8-Р. Национальная часть кодовой таблицы этого стандарта приведена на
рис. 3.2. Рис. 3.2. Национальная часть кодовой таблицы стандарта КОИ8-Р
В
настоящее время применяется и кодовая таблица, размещенная на странице
СР866 стандарта кодирования текстовой информации, которая используется в
операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы (рис. 3.3, а).
а) б) Рис.
3.3. Национальная часть кодовой таблицы, размещенная на странице СР866
(а) и на странице СР1251 (б) стандарта кодирования текстовой информации
В
настоящее время для кодирования кириллицы наибольшее распространение
получила кодовая таблица, размещенная на странице СР1251
соответствующего стандарта, которая используется в операционных системах
семейства Windows фирмы Microsoft (рис. 3.2, б). Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в
котором один символ представляется двухбайтовым двоичным кодом.
Применение этого стандарта – продолжение разработки универсального
международного стандарта, позволяющего решить проблему совместимости
национальных кодировок символов. С помощью данного стандарта можно
закодировать 216 = 65536 различных символов. На рис. 3.4 приведена кодовая таблица 0400 (русский алфавит) стандарта Unicode. Рис. 3.4. Кодовая таблица 0400 стандарта Unicode
Поясним сказанное, касающееся кодирования текстовой информации, на примере.
Пример 3.1Закодировать
слово «Компьютер» в виде последовательности десятичных и
шестнадцатеричных чисел, используя кодировку СР1251. Какие символы будут
отображены в кодовых таблицах СР866 и КОИ8-Р при использовании
полученного кода.
Последовательности шестнадцатеричного и двоичного кода слова «Компьютер» на основе кодировочной таблицы СР1251 (см. рис. 3.3, б) будут выглядеть следующим образом: Данная кодовая последовательность в кодировках СР866 и КОИ8-Р приведет к отображению следующих символов: Для
преобразования русскоязычных текстовых документов из одного стандарта
кодирования текстовой информации в другой используются специальные
программы – конверторы. Конверторы обычно встраиваются в другие
программы. Примером может служить программа браузер – Internet Explorer (IE), которая имеет встроенный конвертор. Программа браузер – это специальная программа для просмотра содержимого Web-страниц в
глобальной компьютерной сети Интернет. Воспользуемся этой программой
для подтверждения полученного в примере 3.1 результата отображения
символов. Для этого выполним следующие действия.
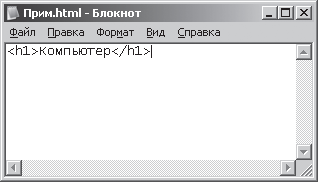
1. Запустим программу Блокнот (NotePad). Программа Блокнот в операционной системе Windows ХР запускается с помощью команды: [Кнопка Пуск –
Программы – Стандартные – Блокнот]. В открывшемся окне программы
Блокнот напечатаем слово «Компьютер» с использованием синтаксиса языка
разметки гипертекстовых документов – HTML (Hyper Text Markup Language). Этот
язык используется для создания документов в Интернете. Текст должен
выглядеть следующим образом: <h1>Компыотер</h1>, где
<h1> и </h1> теги (специальные конструкции) языка HTML для разметки заголовков. На рис. 3.5 представлен результат этих действий. Рис. 3.5. Отображение текста в окне Блокнот
Сохраним
этот текст, выполнив команду: [Файл – Сохранить как…] в соответствующей
папке компьютера, при сохранении текста файлу присвоим имя – Прим, с
расширением файла. html.
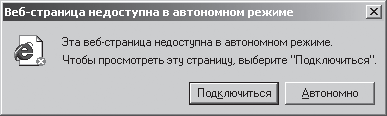
2. Запустим программу Internet Explorer, выполнив команду: [Кнопка Пуск – Программы – Internet Explorer]. При запуске программы появится окно, представленное на рис. 3.6 Рис. 3.6. Окно доступа в автономный режим
Выберем и активизируем кнопку Автономно при этом не произойдет подключение компьютера к глобальной сети Интернет. Появится основное окно программы Microsoft Internet Explorer, представленное на рис. 3.7. Рис. 3.7. Основное окно Microsoft Internet Explorer
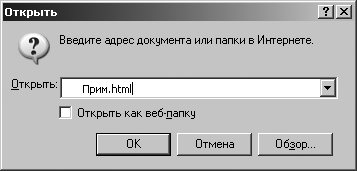
Выполним следующую команду: [Файл – Открыть], появится окно (рис. 3.8), в котором необходимо указать имя файла и нажать кнопку ОК или нажать кнопку Обзор… и найти файл Прим.html. Рис. 3.8. Окно «Открыть»
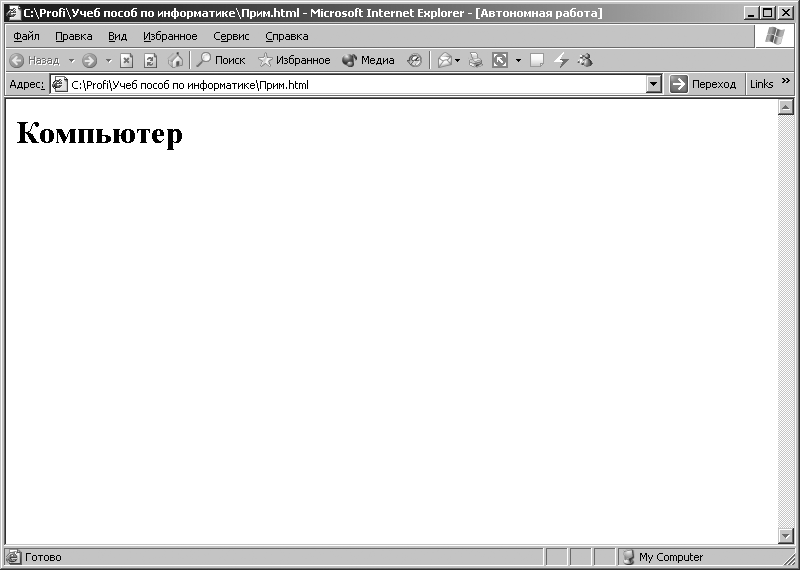
Основное
окно программы Internet Explorer примет вид, показанный на рис. 3.9. В
окне отобразится слово «Компьютер». Далее, используя верхнее меню
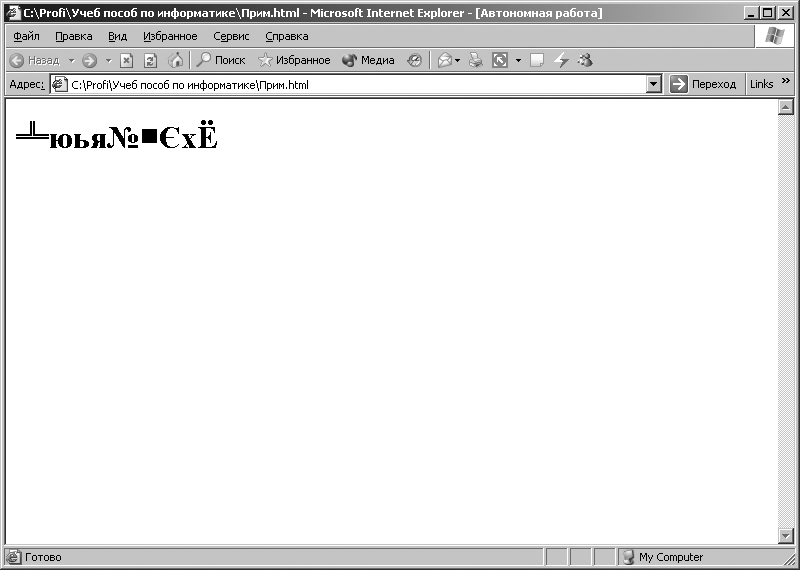
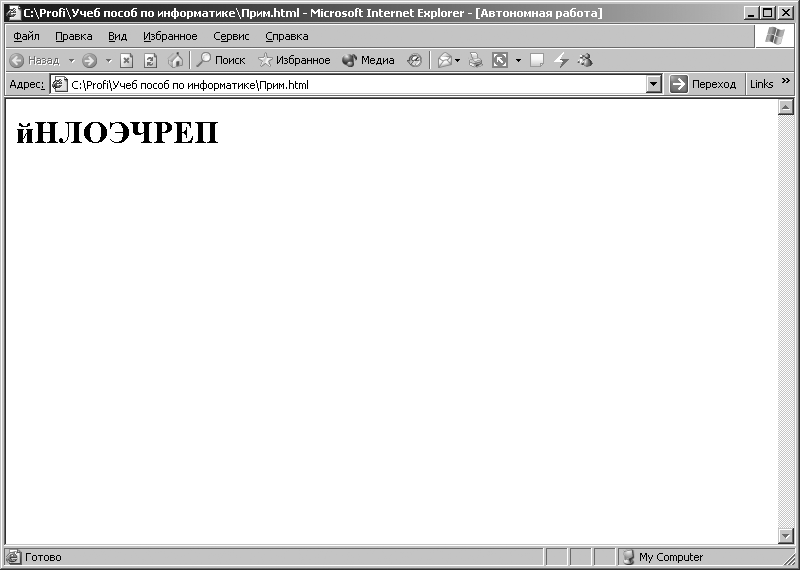
программы Internet Explorer, выполним следующую команду: [Вид – Кодировка – Кириллица (DOS)]. После выполнения этой команды в окне программы Internet Ехplorer отобразятся символы, показанные на рис. 3.10. При выполнении команды: [Вид – Кодировка – Кириллица (KOI8-R) ] в окне программы Internet Explorer отобразятся символы, показанные на рис. 3.11. Рис. 3.9. Символы, отображаемые при кодировке СР1251 Рис. 3.10. Символы, отображаемые при включении кодировки СР866 для кодовой последовательности, представляемой в кодировке СР1251 Рис. 3.11.
Символы, отображаемые при включении кодировки КОИ8-Р для кодовой
последовательности, представляемой в кодировке СР1251
Таким образом, полученные с помощью программы Internet Explorer последовательности
символов совпадают с последовательностями символов, полученных с
помощью кодовых таблиц СР866 и КОИ8-Р в примере 3.1.
|