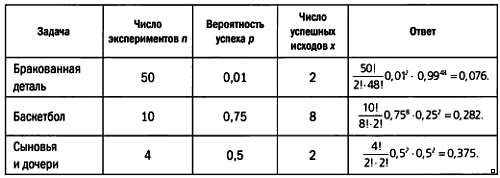
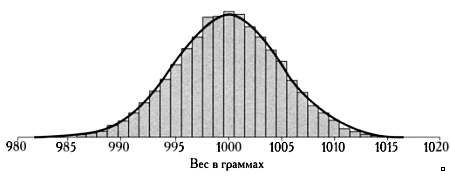
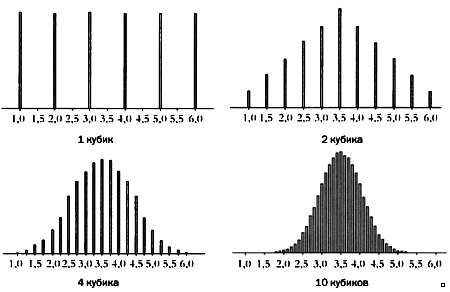
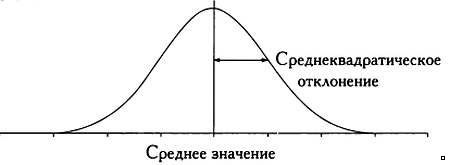
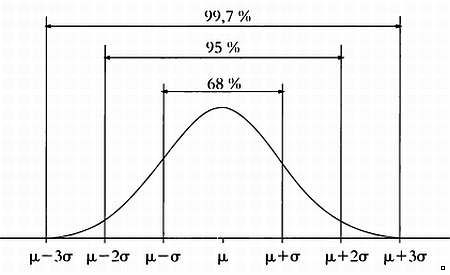
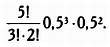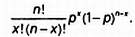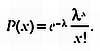Предмет математики настолько серьезен, что нужно
не упускать случая, сделать его немного занимательным".
Блез Паскаль
- Р Р‡.МессенРТвЂВВВВВВВВжер
- ВКонтакте
- РћРТвЂВВВВВВВВнокласснРСвЂВВВВВВВВРєРСвЂВВВВВВВВ
- Telegram
- Viber
- РњРѕР№ Р В Р’В Р РЋРЎв„ўР В Р’В Р РЋРІР‚ВВВВВВВВРЎР‚
- Blogger