Планирование
использования ресурсов для успешного решения тех или иных задач может
оказаться крайне сложным даже для опытного человека. Такое планирование
используется во всех областях, начиная от не слишком важных задач,
например планирования учебного расписания, распределения аудиторий,
лабораторий и аудиовизуальных материалов, и заканчивая крайне важным
планированием ресурсов при тушении лесных пожаров или борьбе с другими
стихийными бедствиями.
Автоматические
рассуждения крайне просты для человека, но невероятно сложны для машин.
По сути, способность рассуждать в немалой степени является
отличительным признаком людей, и ключевые особенности рассуждений до сих
пор не слишком понятны нейробиологам. Для имитации рассуждений человека
инженеры разработали ряд очень интересных приемов, которые применяются,
к примеру, при тушении лесных пожаров.
Сегодня
многие пожарные службы используют системы планирования с искусственным
интеллектом. Как правило, при обнаружении лесного пожара средних
размеров специалисту экстренной службы требуется до полутора часов на
разработку плана тушения. Этот план подробно описывает все действия,
которые следует выполнять всеми доступными средствами в зависимости от
характеристик местности, погодных условий и так далее. Однако
специалисты часто сталкиваются со следующей проблемой: условия в районе
пожара непрерывно меняются, и этот процесс идет так быстро, что человек
попросту не успевает изменить план действий. В результате многие службы
пытаются внедрить автоматизированные системы, способные составить план
тушения пожара за несколько секунд. Система фиксирует такие параметры,
как рельеф местности, погодные условия, проезды к зоне пожара, доступные
авиационные и наземные средства, а также возможность координировать
действия с другими подразделениями и центрами управления, на основе этих
параметров она составляет план и отправляет его на проверку
человеку-эксперту.

Тушение лесного пожара требует координирования многочисленных человеческих и материальных ресурсов.
Может
случиться так, что в данный момент одна единица техники не
задействована, и система предлагает два варианта: перевести ее в зону,
где бушует пожар, либо отправить ее на тушение очагов пожара в другую,
менее опасную область, расположенную ближе. Как система определит, какой
из вариантов лучше? Логично, что конечная цель — потушить пожар,
следовательно, кажется более естественным направить технику туда, где
пожар сильнее. С другой стороны, на переброску тех ники может уйти
несколько часов, а всего в нескольких минутах езды очаги пожара не
представляют большой опасности, и их можно потушить относительно легко.
Как
объективно оценить преимущества от тушения пожара в определенной
области с учетом расстояния до нее и затраченного времени? Именно такой
оценки требует классическая, неинтеллектуальная система планирования. Но
при тушении пожара используется не одна, а несколько десятков единиц
наземной и воздушной техники.
Также
можно учесть новые переменные, например скорость ветра и прогноз
погоды, возможные дожди, расположение жилья, природоохранных зон и так
далее. При таком обилии переменных становится понятной огромная
потребность в интеллектуальной системе, способной принимать решения с
учетом всех перечисленных факторов и на основе нечетких параметров.
* * *
НЕЧЕТКАЯ ЛОГИКА
Нечеткая
логика — раздел математической логики, приближающий логические действия
и методы к естественным, человеческим рассуждениям. Как правило, в
реальной ситуации ничто не делится на белое и черное, но в классической
логике, в частности в булевой, переменные могут быть только истинными
или ложными, что вынуждает рассматривать лишь крайности.
К
примеру, на вопрос, хорошо или плохо играет вратарь футбольной команды
из первого дивизиона чемпионата Казахстана, дать однозначный ответ
нельзя: в сравнении с элитой мирового футбола он наверняка не слишком
хорош, но по сравнению с вратарем моей районной команды он будет
первоклассным игроком.
Поэтому
переменные нечеткой логики принимают значения не «истина» или «ложь», а
вещественные значения, заключенные на интервале от 0 до 1, где значению
1 соответствует «истина», 0 — «ложь». Если мы обозначим через 0
неспособность отразить любой удар, а через 1 — уровень лучшего вратаря
мира, то вратарь казахской команды получит вполне достойную оценку в
0,73.
* * *
Для
решения задач такого типа обычно используются классические алгоритмы
поиска, применяемые в искусственном интеллекте, в частности поиск с
возвратом (back-tracking) или метод ветвей и границ (branch-and-bound).
Оба этих алгоритма действуют схожим образом: по сути, они разворачивают
комбинаторное дерево и обходят его в поисках оптимального варианта.
Развертывание комбинаторного дерева происходит достаточно просто. На
первом этапе создается дерево, содержащее все возможные планы (вспомните
понятия, которые мы объяснили в первой главе, рассказывая об
интеллектуальном алгоритме, способном определять оптимальные ходы в
шахматной партии). Далее с помощью интеллектуальных алгоритмов
последовательно отсекаются те ветви, которым соответствуют нереальные
планы либо планы, нарушающие ограничения или ведущие к неоптимальному
решению.
Важное
отличие метода поиска с возвратом от метода ветвей и границ заключается
в том, что первый метод состоит в обходе дерева в глубину, второй — в
обходе в ширину. Это различие крайне важно: в зависимости от
представления задачи отсечение той или иной ветви может иметь разную
эффективность.
Последовательное
отсечение ветвей дерева по мере обхода абсолютно необходимо — в
противном случае, как и почти во всех комбинаторных задачах, число
планов, а значит, и число ветвей, будет так велико, что его нельзя будет
обойти за разумное время. Чтобы ускорить отсечение ветвей, в методах,
основанных на обходе дерева, обычно используются так называемые
эвристики (или формальное представление интуитивных понятий), которые
может применить специалист предметной области, чтобы определить: та или
иная ветвь не приведет к нужному результату, и ее необходимо отсечь как
можно скорее. Разумеется, если мы отсечем ветвь, которая соответствует
неосуществимому плану, на раннем этапе алгоритма, то можем сэкономить
несколько часов вычислений — с переходом на более высокие уровни число
вариантов, которые необходимо проанализировать, возрастает
экспоненциально.
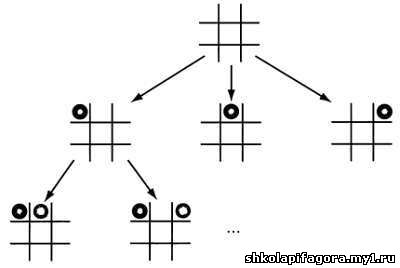
Простой пример дерева планирования для игры «крестики-нолики».
* * *
ТЕОРЕМА «БЕСПЛАТНОГО ОБЕДА НЕ БЫВАЕТ»
Теорема
под названием «бесплатного обеда не бывает» (no-free lunch) гласит: не
существует алгоритма, позволяющего получить оптимальные решения всех
возможных задач. Теорема получила свое любопытное название на основе
метафоры о стоимости блюд в различных ресторанах. Допустим, что
существует определенное число ресторанов (каждый из них обозначает
определенный алгоритм прогнозирования), где в меню различным блюдам
(каждое блюдо обозначает определенную задачу прогнозирования)
сопоставлена цена (или качество решения этой задачи, которое позволяет
получить рассматриваемый алгоритм). Человек, который любит поесть и при
этом не прочь сэкономить, может определить, какой ресторан предлагает
его любимое блюдо по самой выгодной цене. Вегетарианец, сопровождающий
этого обжору, наверняка обнаружит, что его любимое вегетарианское блюдо в
этом ресторане стоит намного дороже. Если обжора захочет полакомиться
бифштексом, он выберет ресторан, где бифштекс подают по самой низкой
цене. Но у его друга-вегетарианца при этом не останется другого выбора,
кроме как заказать единственное вегетарианское блюдо в этом ресторане,
пусть даже по заоблачной цене. Это очень точная метафора ситуации, когда
необходимость использования определенного алгоритма для решения
конкретной задачи приводит к гарантированно неоптимальным результатам.
Исследователи прилагают огромные усилия для создания супералгоритма или
суперметода, позволяющего составить идеальный план, но в конечном итоге
неизменно сталкиваются с определенным множеством данных или контекстом, в
котором оптимальные результаты показывает другой алгоритм.
Теорема
имеет еще одно важное следствие: если мы тратим много сил на
корректировку алгоритма, чтобы добиться идеальных результатов для
определенных исходных данных, эти корректировки гарантированно приведут к
ухудшению работы алгоритма для другого множества данных. Вывод: любой
алгоритм будет либо работать идеально для небольшого числа случаев и
плохо — во всех остальных, либо будет демонстрировать посредственные
результаты во всех случаях. соответствует неосуществимому плану, на
раннем этапе алгоритма, то можем сэкономить несколько часов вычислений —
с переходом на более высокие уровни число вариантов, которые необходимо
проанализировать, возрастает экспоненциально.