Прекрасно
известно, что интуиция, не подкрепленная размышлениями, — злейший враг
статистики и теории вероятностей. Многие думают, что при анализе данных
большой объем входных данных (но не выборок) позволит получить больше
информации, а следовательно, и больше знаний. С этим заблуждением
традиционно сталкиваются начинающие специалисты по интеллектуальному
анализу данных, и распространено оно настолько широко, что специалисты
называют его проклятием размерности. Суть
проблемы заключается в том, что при добавлении к математическому
пространству дополнительных измерений его объем возрастает
экспоненциально. К
примеру, 100 точек (102) — достаточная выборка для единичного
интервала, при условии, что расстояние между точками не превышает 0,01.
Но в кубе единичной стороны аналогичная выборка должна содержать уже
1000000 точек (106), а в гиперкубе размерностью 10 и с длиной стороны,
равной 1, — уже 1020 точек. Следовательно, чтобы при добавлении новых
измерений выборка по-прежнему охватывала пространство должным образом
(иными словами, чтобы плотность математического пространства оставалась
неизменной), объемы выборок должны возрастать экспоненциально. Допустим,
что мы хотим найти закономерности в результатах парламентских выборов и
располагаем множеством данных об избирателях и их предпочтениях. Часть
имеющихся данных, к примеру рост избирателей, возможно, не будет иметь
отношения к результатам голосования. В этом случае лучше исключить
переменную «рост», чтобы повысить плотность выборок избирателей в
математическом пространстве, где мы будем работать. Именно проклятие размерности стало причиной появления целого раздела статистики под названием отбор характеристик (англ, feature selection).
В этом разделе изучаются различные математические методы, позволяющие
исключить максимально большой объем данных, не относящихся к
рассматриваемой задаче. Методы отбора характеристик могут варьироваться
от исключения избыточной или связанной информации до исключения
случайных данных и переменных, имеющих постоянное значение (то есть
переменных, значения которых на множестве выборок практически не
меняются). В качестве примера приведем переменную «гражданство». Логично,
что ее значение будет одинаковым для всех или почти всех избирателей,
следовательно, эта переменная не имеет никакой ценности. Чаще
всего используется такой метод отбора характеристик, как метод главных
компонент. Его цель — определение проекции, в которой вариация данных
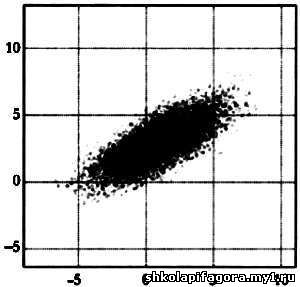
будет наибольшей. В примере, представленном на следующем рисунке, две
стрелки указывают две главные компоненты с максимальной вариацией в
облаке точек. Максимальная вариация указана более длинной стрелкой. Если
мы хотим снизить размерность данных, то две переменные, откладываемые
на осях абсцисс и ординат, можно заменить новой переменной — проекцией
выборок на компоненту, указываемую длинной стрелкой. На этом графике стрелки указывают направления, в которых вариация данных будет наибольшей. * * * А ЭТО КТО? РАСПОЗНАВАНИЕ ЛИЦ Многие
современные фотоаппараты способны во время съемки распознавать лица.
Например, цифровые фотоаппараты часто содержат функцию, позволяющую
определить число лиц на фотографии и автоматически настроить параметры
съемки так, чтобы все лица оказались в фокусе. Социальная
сеть Facebook также использует функцию распознавания лиц, способную
определять людей на фотографиях, загружаемых пользователем. Как же
действуют подобные функции?  Большинство
функций распознавания лиц основаны на методе главных компонент. Сначала
проводится обучение системы на множестве изображений различных лиц. В
ходе обучения система определяет главные компоненты в результате анализа
нескольких фотографий одного лица и множества фотографий всех лиц. В
действительности система всего лишь запоминает наиболее характерные
черты лица каждого человека, чтобы потом распознать его. Таким
образом, для нового изображения система извлекает информацию о главных
компонентах и сравнивает ее с информацией о компонентах, полученной в
ходе обучения. В зависимости от процента совпадения система способна
определить, какая часть тела изображена на фотографии, лицо или нога, и
даже распознать, какому человеку принадлежит это лицо. * * * Метод
главных компонент заключается в поиске линейного преобразования,
позволяющего получить новую систему координат для исходного множества
выборок. В
этой системе координат первая главная компонента будет отражать
наибольшую вариацию, вторая — следующую по величине вариацию и так
далее. Число компонент может быть любым. Одно из преимуществ этого
метода заключается в том, что на промежуточных этапах поиска компонент с
наибольшей вариацией можно определить, какую часть вариации переменных
объясняет каждая компонента. К примеру, первая главная компонента может
объяснить 75 % вариации, вторая — 10 %, третья — 1 % и так далее. Так
можно уменьшить размерность множества данных и при этом гарантировать,
что новые измерения, которые придут на смену исходным, будут объяснять
минимум вариации данных. Рекомендуется, чтобы вариация, в сумме
описываемая выделенными компонентами, составляла около 80 %. Несмотря
на все преимущества и относительную простоту метода главных компонент
(сегодня этот метод входит в стандартную поставку всех пакетов
статистических программ), по мере увеличения числа измерений в модели
сложность расчетов возрастает, и вычисления могут оказаться
непосильными. В подобных случаях используются два других метода отбора
характеристик: жадный прямой отбор (greedy forward selection) и жадное обратное исключение (greedy backward elimination).
Оба этих метода обладают серьезными недостатками: они требуют
выполнения огромного объема расчетов, при этом вероятность выбора
наиболее подходящих характеристик невысока. Однако основная идея этих
методов и ее реализация просты, а объем необходимых вычислений для
большого числа измерений все же не так высок, как при использовании
метода главных компонент. Это объясняет, почему жадный прямой отбор и
жадное обратное исключение стали так популярны среди специалистов по
интеллектуальному анализу данных. * * * ЖАДНЫЕ АЛГОРИТМЫ Жадные
алгоритмы — разновидность алгоритмов, в которых для определения
следующего действия (при решении задач планирования, поиска или
обучения) всегда выбирается вариант, ведущий к максимальному увеличению
некоего градиента в краткосрочной перспективе. Достоинство
жадных алгоритмов заключается в том, что они способны очень быстро
найти максимальное значение определенных математических функций. Для
сложных функций, имеющих несколько максимумов, жадные алгоритмы,
напротив, обычно останавливаются на одном из локальных максимумов, так
как не могут оценить задачу в целом. В итоге жадные алгоритмы
оказываются не вполне эффективны, так как результатом их работы часто
является субоптимум функции. * * * Как
следует из названия, один из этих методов является прямым, а другой —
обратным, однако оба используют один принцип. Представьте, что мы хотим
отобрать характеристики, точнее всего описывающие тенденции голосования
на парламентских выборах. Имеем пять известных характеристик выборки:
покупательная способность, родной город, образование, пол и рост
избирателя. Будем использовать для анализа тенденций нейронную сеть.
Применив жадный прямой отбор, выберем первую переменную в задаче и
смоделируем данные с помощью нейронной сети, используя только эту
переменную. После того как модель построена, оценим точность прогноза и
сохраним полученную информацию. Повторим аналогичные действия для всех
остальных переменных по отдельности. По завершении анализа выберем
переменную, для которой были получены лучшие результаты, и повторим
моделирование с последующей оценкой модели, но уже для двух переменных.
Предположим, что лучшие результаты были получены для переменной
«образование». Проверим все возможные сочетания переменных, в которых
первой переменной будет «образование». Получим модели «образование и
родной город», «образование и пол», «образование и рост». И вновь,
проанализировав четыре сочетания, выберем лучшее из них, к примеру
«образование и покупательная способность», после чего повторим описанные
выше действия уже для трех переменных, две из которых будут
фиксированы. Этот процесс будет повторяться до тех пор, пока с
добавлением очередной переменной точность новой модели относительно
предыдущей, содержащей на одну переменную меньше, не перестанет
возрастать. Жадное
обратное исключение проводится прямо противоположным образом: в
качестве исходной выбирается модель, содержащая все переменные, затем из
нее последовательно исключаются переменные так, чтобы качество модели
не ухудшалось. Как
можно догадаться, этот метод является не слишком интеллектуальным: он
не гарантирует, что будет найдено наилучшее сочетание переменных, а
также предполагает значительный объем вычислений, поскольку на каждом
этапе необходимо выполнять моделирование заново. Ввиду
важных недостатков существующих методов отбора характеристик на
специализированных конференциях постоянно предлагаются новые методы. Они
обычно описываются тем же принципом, что и метод главных компонент, то
есть заключаются в поиске новых переменных, которые замещают исходные и
повышают плотность информации. Подобные переменные называются
латентными. Они используются во множестве дисциплин, однако наибольшее
распространение получили в общественных науках. Такие характеристики,
как качество жизни в обществе, доверие участников рынка или
пространственное мышление человека, — латентные переменные, которые
нельзя измерить напрямую. Они измеряются и выводятся по результатам
совокупного анализа других, более осязаемых характеристик. Латентные
переменные обладают еще одним преимуществом: они сводят несколько
характеристик в одну, тем самым уменьшая размерность модели и упрощая
работу с ней.
|