Визуализация
данных — дисциплина, изучающая графическое представление данных, как
правило многомерных. Эта дисциплина стала популярной вскоре после
образования современных государств, способных систематически собирать
данные о развитии экономики, общества и производственных систем. В
действительности визуализация данных и анализ данных — смежные
дисциплины, так как многие средства, методы и понятия, используемые для
упрощения визуализации, возникли в рамках анализа данных, и наоборот. Возможно,
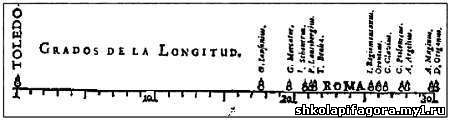
автором первой известной визуализации статистических данных был Михаэль
ван Лангрен, который в 1644 году изобразил на диаграмме 12 оценок
расстояния между Толедо и Римом, предложенных 12 разными учеными. Слово
«ROMA» («РИМ») указывает оценку самого Лангрена, а маленькая размытая
стрелка, изображенная под линией примерно в ее центре, — корректное
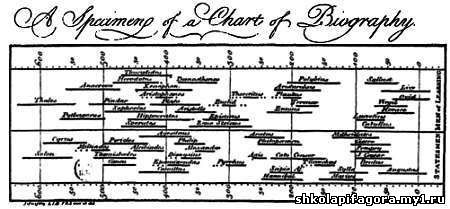
расстояние, вычисленное современными методами. Еще в XVIII веке Джозеф Пристли составил диаграмму, где изобразил, в какое время жили некоторые выдающиеся деятели античности. В
том же столетии, благодаря трудам Иммануила Канта, который утверждал,
что именно представление делает объект возможным, а не наоборот, стало
понятно, что нельзя вести споры о знаниях или реальности, не учитывая,
что эти самые знания и реальность создает человеческий разум. Так
представление и визуализация данных заслуженно заняли важнейшее место в
науке. Позднее,
во время Промышленной революции, начали появляться более сложные методы
представления данных. В частности, Уильям Плейфэр создал методы,
позволяющие представить изменение объемов производства, связав их с
колебаниями цен на пшеницу и с величиной заработной платы при разных
правителях на протяжении более 250 лет. 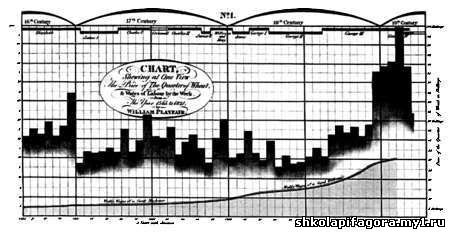 Благодаря
вычислительной технике специалисты в сфере визуализации данных начали
понимать, каким должно быть качественное представление данных для их
быстрой интерпретации. Один из важнейших моментов, которые следует
принимать во внимание (помимо самих данных, модели представления и
графического движка, используемого для визуализации), — ограниченные
способности восприятия самого аналитика, конечного потребителя данных. В
мозгу аналитика происходят определенные когнитивные процессы, в ходе
которых выстраивается ментальная модель данных. Однако эти когнитивные
процессы страдают из-за ограниченности нашего восприятия: так.
большинство из нас неспособны представить себе больше четырех или пять
измерений. Чтобы упростить построение моделей, необходимо учитывать все
эти ограничения. Качественная визуализация данных должна представлять
информацию в иерархическом виде с различными уровнями подробностей.
Также визуализация должна быть непротиворечивой и не содержать
искажений. В ней следует свести к минимуму влияние данных, которые не
содержат полезной информации или могут вести к ошибочным выводам.
Рекомендуется дополнять визуализацию иными статистическими данными,
указывающими статистическую значимость различной информации. Для
достижения всех этих целей используются стратегии, подобные
рассмотренным в главе, посвященной анализу данных. Первая из них
заключается в снижении размерности с помощью уже описанных методов, в
частности, путем ввода латентных переменных. Вторая стратегия состоит в
снижении числа выборок модели путем их разделения на значащие группы.
Этот процесс называется кластеризацией (английское слово «кластер» можно
перевести как «гроздь», «пучок»). Кластерный
анализ состоит в разделении множества результатов наблюдений на
подмножества — кластеры, так, чтобы все результаты, принадлежащие к
одному кластеру, обладали некими общими свойствами, необязательно
очевидными. Кластеризация данных значительно упрощает их графическое
представление, а также позволяет специалистам по визуализации понять
изображаемые данные. Существует множество алгоритмов кластеризации, и
каждый из них обладает особыми математическими свойствами, которые
делают его пригодным для тех или иных типов данных.
|